

Join Hack Club Horizons! Ship your projects and fly to your first hackathon →
We can read all the content on websites, but wouldn't it be cool if we could automatically read specific data from websites whenever you wanted? If this interested you, this workshop is for you. I will be showing you how to use webscraping to create a tool that can gather current COVID data and displays it as text.
Note: not all webpages can be read using this technique. If data is loaded in using ajax or after the inital page request this method may not work.

Prerequisites
You should have a basic understanding of HTML and Python and how to use variables and objects.
Setup

We will be using repl.it, an online code editor that allows you to write and run code from any computer!
Spin up a Python3 repl by clicking here.
Before we can start coding, we need to install a couple of external libraries. Follow the image below to find where to add the packages. Once in this menu you will need to install beautifulsoup4, requests, and lxml.
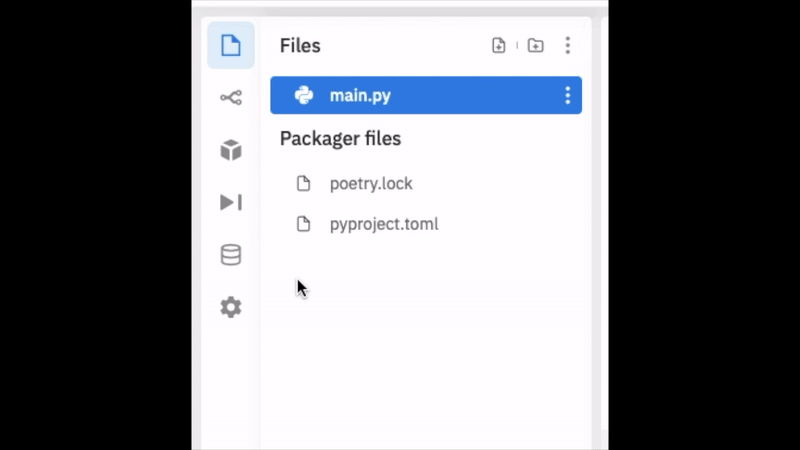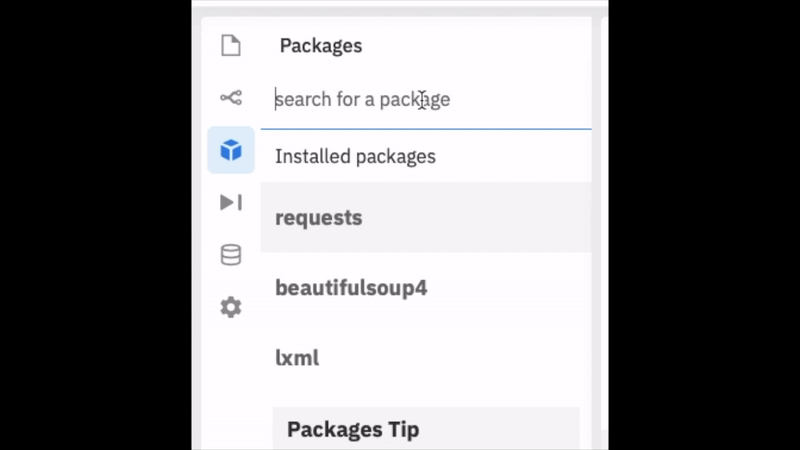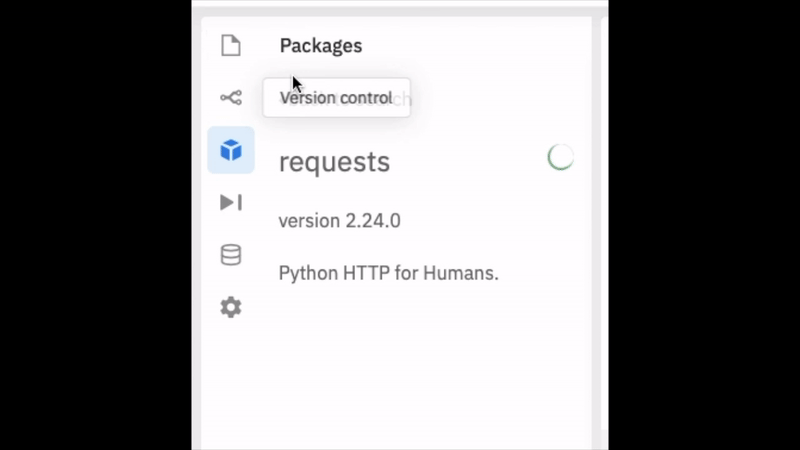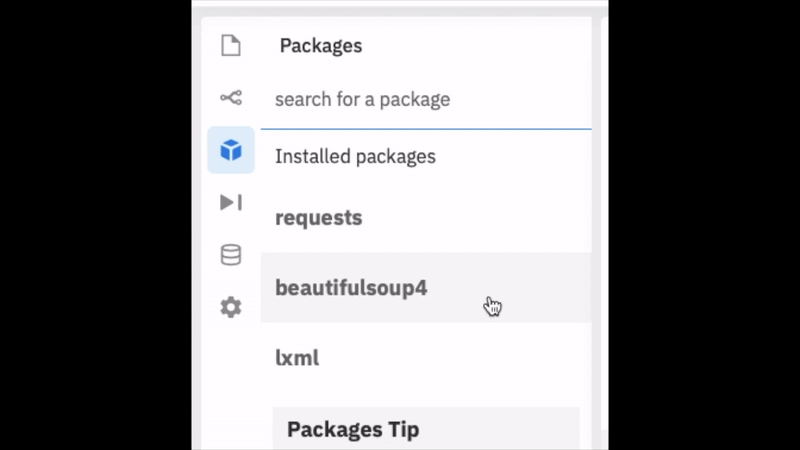
What each package does
requests is a Python library which makes it very easy to request a webpage. Requesting a webpage means we give the requests library a url and it returns all the HTML from the url we provide.
lxml is a C package used by BeautifulSoup that parses the HTML. When we request the HTML it will just be a big block of text. When lxml parses the HTML this allows Python to understand the HTML and allows us the ability to search for and find things in the HTML.
beautifulsoup4 is a Python library that uses the parsed HTML from lxml to search fo and find specific HTML elements and data. This allows us to easily get the information we want from a large webpage full of data.
Learn more about the packages:
Lets start coding!

Once you've installed the packages, open the main.py file in the sidebar on the left. Then, import the packages you just installed.
from bs4 import BeautifulSoup as bs
import requests
Now we can start webscraping! We will begin by requesting our webpage and extracting the HTML from the request object.
url = 'https://ncov2019.live/data'
# request the website
r = requests.get(url)
# get the HTML from the request
page = r.text
Next we will create the BeautifulSoup object and use lxml to parse the HTML.
soup = bs(page, 'lxml')
Now that we have our BeautifulSoup object we can go all of the HTML!
Working with the parsed HTML

In the next step, we'll be working with data from an HTML table. The website that contains the COVID data uses HTML tables. The structure of an HTML table can be a little confusing so lets break it down first.
Here's an example of an HTML table:
<table>
<tr>
<td>Country</td>
<td>Cases</td>
<td>Column</td>
<td>Column 2</td>
</tr>
<tr>
<td>United States</td>
<td>1,000,000</td>
<td>Column data</td>
<td>Column 2 data</td>
</tr>
<tr>
<td>Canada</td>
<td>100,000</td>
<td>Column data</td>
<td>Column 2 data</td>
</tr>
</table>
It first involves the table tag, within this table it contains rows (tr), and lastly each row contains columns (td). We just need to roughly understand the table to scrape it. Simply put, the table is made up of rows and within each row there are columns.
Some tables can be really large, like the ones used on the COVID data website, but by utilizting for loops in Python we can easily traverse the tables.
Python time!
We're going to use BeautifulSoup to find an HTML table element. We want to find a specific table by ID sortable_table_world as seen in the picture.
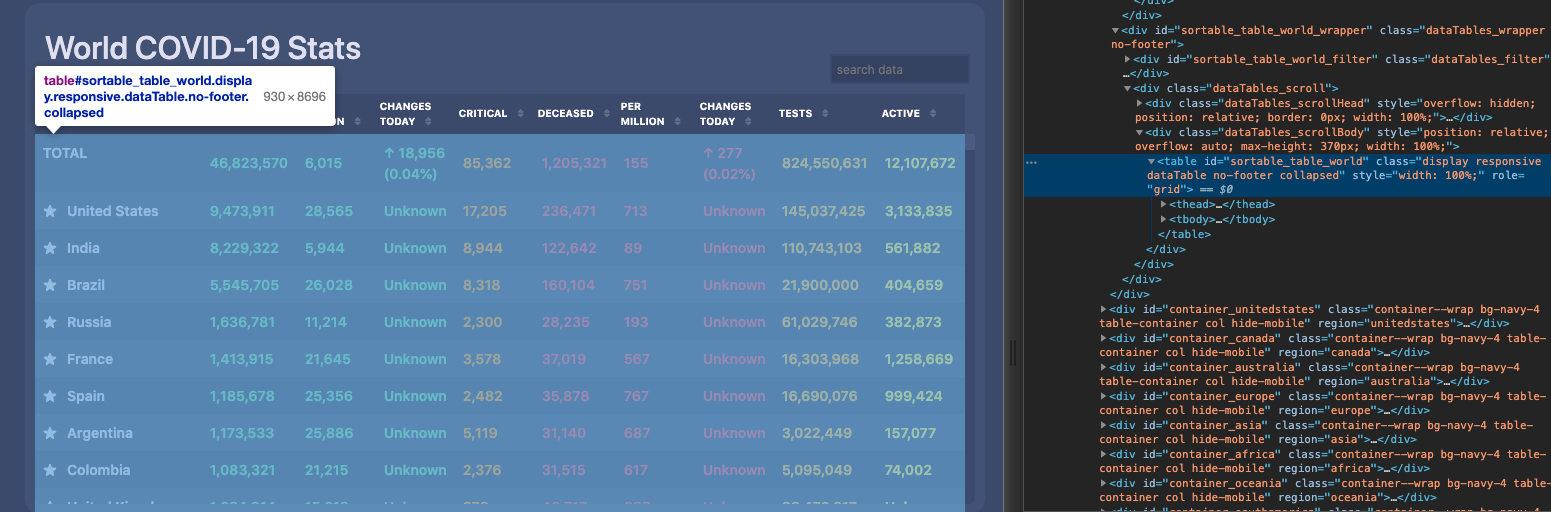
The code below finds the first table that matches that ID by using the find() function from the BeautifulSoup library. We are looking for a very specific table as shown in the picture below. We pass in 'table' to specify we want an HTML table and pass in a dictionary that specifiies we want the table with the ID sortable_table_world.
# get world data table
table = soup.find('table', attrs={'id':'sortable_table_world'})
After this code runs we now have a new BeautifulSoup object called table that contains the table and child elements within that table.
With table we will use the findAll() function from the BeautifulSoup library. When we run the findAll() function on the variable table BeautifulSoup will only find items inside our table. This function allows us to all the HTML elements that fit our parameter. In this case we pass in 'tr' to get every row inside our table. This function will return a Python list with BeautifulSoup objects of every row in our table.
# get table rows
tableRows = table.findAll('tr')
Now that we have all the table rows in a Python list (tableRows), we can iterate through the list. Doing this will allow us to choose which countries' data we want.
Before we start iterating, there are some things we need to adress regarding the data. The data doesn't come as simple text and numbers. For our project the website returns data with whitespacing as seen below. Included with our data are newlines and random spaces.
The code below is an example that returns a piece of data from our table.
tableCols = tableRows[1].findAll('td')
tableCol = tableCols[0]
tableCol.text
> "\r\n TOTAL\r\n "
With Python we can use the .strip() function on the string. The .strip() function clears away all whitespacing from the begining and end of a string. Below is an example of the code we can use to get clean data.
tableCol.text.strip()
> "TOTAL"
Now that we got that handled lets get to proccessing the rest of our data!
We begin with creaing a simple for loop to iterate over the data. Our loop will loop through every row in our table. This is also reffered to as a for each loop in other programming languages like Java.
for row in tableRows[1:]:
# Whatever is in here will run for every row in our table
You may have noticed tableRows[1:] has a weird bracket thing attached to it. This is list splicing. In Python this allows a programmer to control how much of the list they want to use. The general structure looks like this [starting value (inclusive) : ending value (exclusive) : step (how many items skip)]. Each value is optional which is why in our example only includs a 1, no ending value, and no step value.
By default when putting a list in a for loop the brakcet would be [::] meaning that it will start at the begining, stop at the end, and go up by one. For our for loop we want to skip the first row because the first row is the table header (column names).
Next we add an if statment that checks if the current row is the United States.
for row in tableRows[1:]:
if 'United States' == row.find('td').text[2:].strip():
# Do something if the current row is the United States
This if statment may seem long and complicated but lets break it down into small parts. The first part, 'United States' == checks if whatever is on the other side of the double equals is the words "United States". On the other side we have to get the country name.
As you can remember from before, tableRows contains a list of BeautifulSoup objects that contains all the rows from our table. Within these rows are all the columns. For the table we are using the country name is in the first column or the first td element in the row.
To get the current row's country we use BeautifulSoup to find the first column in the row with row.find('td'). This returns a weird string with whitespaces as we have seen before as well as some random characters. To get rid of these uneeded characters we use [2:] which is the same as list splicing except for strings, and we use .strip() to clear away excess whitespacing.
Now we have code that finds the country we want from all the rows in our table, the last step is to display the data!
for row in tableRows[1:]:
if 'United States' == row.find('td').text[2:].strip():
columns = row.findAll('td')
print(columns[0].text[2:].strip())
print(f'Confirmed Cases: {columns[1].text.strip()}')
print(f'New Cases: {columns[3].text.strip()}')
print(f'Critical Cases: {columns[5].text.strip()}')
> United States
> Confirmed Cases: 9,566,690
> New Cases: 28,845
> Critical Cases: 88,127
Once you find the row of the country we want information about we can display any data we want. To start we run row.findAll('td') to get all the columns in the row. We didn't do this before because if we did, the code would have been slower compared to just using row.find('td'). From there you can print any column data with this code: print(f'Anything you want here: {columns[any column number].text.strip()}'). If you are unsure what columns you want you can run print(columns) and select as many of the columns as you want.
Our previous example showed how to find data on one country but as we know the world has hundreds of countries. Here is some similar code for multiple countries.
countries = ['United States', 'Spain', 'Canada']
for row in tableRows[1:]:
if row.find('td').text[2:].strip() in countries:
columns = row.findAll('td')
print(columns[0].text[2:].strip())
print(f'Confirmed Cases: {columns[1].text.strip()}')
print(f'New Cases: {columns[3].text.strip()}')
print(f'Critical Cases: {columns[5].text.strip()}\n')
The only difference is we create a python list to store the names of the countries we want to view.
Thats it!
You can now get live COVID19 data, but more importantly you are now primed with knowledge to webscrape anything!
Here is the final code you can view and edit: Final Result and Code

Hacking
You can check out more advanced/in depth projects here.
In this project you will be shown how to use selenium to webscrape. This method will allow you to webscrape pages like Amazon or Google that use ajax to load data as you scroll.
This workshop by Realpython goes more in depth and includes links to other resources that can allow you to webscrape more complicated websites.
Check out some other webscraping projects Webscrape Github Webscrape Currency Exchange Rates Webscrape Hack Club Bank
What now?
Go out there and create your own project! I'm sure you will blow us away
